Engineering an Invisible and Assistive Voice Agent for Clinicians
August 28, 2025
Suki’s mission to create an invisible and assistive voice-based clinical documentation solution poses several intriguing challenges for engineering design. In this blog post, we will delve into the primary obstacles associated with this task and discuss the approaches employed by the Suki Engineering team to overcome them.
The Mission and its Resulting Technical Problems
Suki’s mission serves as the touchstone for what we strive to accomplish and underscores the technical hurdles that ensue:
We’re reimagining the healthcare tech stack, making it invisible and assistive. We deliver very fast and accurate voice experiences using the latest in natural language processing and machine learning.
Let us delve into some vital elements of our mission in greater detail. These delineate both a solution-oriented approach and significant technical challenges that we need to address.
Invisible and Assistive
An “invisible” digital assistant refers to a technological solution that immerses itself seamlessly into a doctor’s natural working environment and does not require the physician’s attention by forcing them to shift their focus between patient care and documentation. On the other hand, an “assistive” digital assistant refers to a solution that actually aids the doctor in carrying out patient care efficiently and effectively, while remaining unobtrusive. It provides crucial patient information at the doctor’s fingertips and attempts to make documentation a pleasurable, rapid, and intuitive experience. Therefore, an invisible and assistive digital assistant should function no differently than a well-trained medical scribe. It should be an (voice) assistant that the physician can converse with to accurately record information and answer queries in a responsive and precise manner.
Voice Experience
Using voice for dictation is an obvious choice. It is faster, more natural, and efficient for clinical documentation than typing because:
- It enhances the physician’s speed of documentation by eliminating typing and clicking
- It lets doctors speak naturally as they express their medical decision making
- Voice provides a single assistant interface that can switch seamlessly between dictation, query, request, and command
Fast and Accurate
The trade-off between speed and accuracy has always been a challenge. In the case of a voice-based digital assistant, this trade-off is magnified. A slow but highly accurate solution would be frustrating for doctors and could contribute to their burnout. On the other hand, a fast but less accurate solution would require manual interventions to edit words and formatting, impacting the overall efficacy of the solution.
Achieving the right balance between speed and accuracy in the context of voice experiences is non-trivial. This is particularly challenging when handling audio input and transcribing voice to text in real-time while achieving high accuracy for medical dictation, which is a very specialized form of dictation.
NLP and ML
In today’s world, nearly every app boasts about using machine learning (ML), natural language processing (NLP), or artificial intelligence (AI). However, it is crucial to evaluate where these technologies fit into the solution space and deliver distinct value. At Suki, these technologies are not an afterthought, but rather, are employed to power core user cases.
There are a few essential ways in which machine learning and AI play a critical role in Suki. Some examples include:
- Automatic Speech Recognition (ASR): Suki uses a medical ASR that is capable of performing highly accurate, low-latency transcription from voice data. A medical ASR has different requirements from a general purpose ASR as medical terms warrant high accuracy. A mistranscription during a medical dictation more often than not significantly affects the meaning, diagnosis or summary of the note and can even change it completely. For example, the word “hyperglycemia” means excess of glucose in the body whereas the word “hypoglycemia” means deficit of it. Even minor transcription errors in these can potentially change the diagnosis. By combining information about context (e.g., patient age, physician specialty, appointment type) with a medically tuned ASR, the ASR can accurately select from similar terms to create highly-accurate notes.
- Intent Extractor: Suki employs a model that can understand the intents underlying commands from the physician to get an action done and seamlessly switch between dictation and commands. A clinician can dictate a section of a note and then ask Suki to insert a template into another section of the note without needing to tell Suki that you’re done dictating. Suki recognizes that the user has switched to command mode to complete another action.
Solving the problems
To build an effective solution for medical dictation, it is crucial to address the challenges presented by various aspects such as real-time voice transcription, understanding the context of a clinical note, and processing commands. The solution must possess a set of foundational characteristics, including:
- Real-time voice transcription capability for medical dictation
- The ability to understand the context of the US healthcare setting, specifically Electronic Medical Record (EHR) systems, and facilitate doctor’s interactions with EHR data
- Capability to process voice commands, allowing doctors to dictate steps such as “Go to Physical Exam section” instead of being restricted to clicking and typing medical narratives
- Most importantly, the solution should be integrated seamlessly into doctors’ existing workflow without requiring significant changes
While other concerns such as EHR-agnostic data format and storage, auditability of data, and compliance are important, the foundational characteristics listed above are the core components of an effective solution for medical dictation. Let’s see how Suki Engineering approaches them.
Problem 1: Real-time voice transcription for medical dictation
One of Suki’s core skills is real-time voice transcription for medical dictation. While voice-to-text products have been available for some time, their accuracy for medical dictation has only recently become more acceptable. When Suki was built in 2017, there were few solutions that performed reasonably well for medical dictation. Suki uses a dual ASR approach, with one ASR for dictation and the other for commands, to achieve the best balance between processing commands and transcribing speech. Suki’s backend uses wakeword-based audio routing and time segmentation to determine if the transcript is a command or dictation. This ensures that doctors can use Suki in hands-free mode, dictating in different sections of a clinical note seamlessly without compromising user experience. This creates a state transition mechanism:
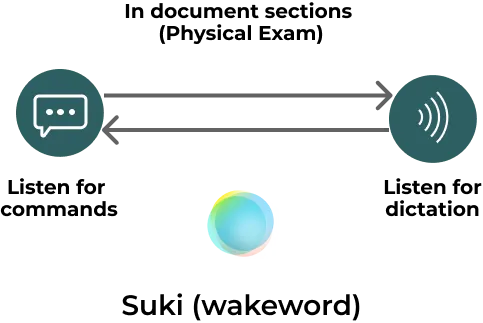
This dual ASR mode helps Suki achieve three things:
- Single interface for dictation and commands
- Optimal accuracy and efficiency for both dictation and commands
- Effective use of specialized ASRs
It also creates a few challenges to be solved:
- Packet ordering in case of delays in transcriptions from different ASRs
- Managing dictation flow with different ASRs
- Clean and transparent state transition between commands and dictations
Building a voice assistant that can seamlessly integrate into a physician’s workflow while accurately transcribing both dictation and commands is a significant technical challenge.
Problem 2: Integrating with EHRs
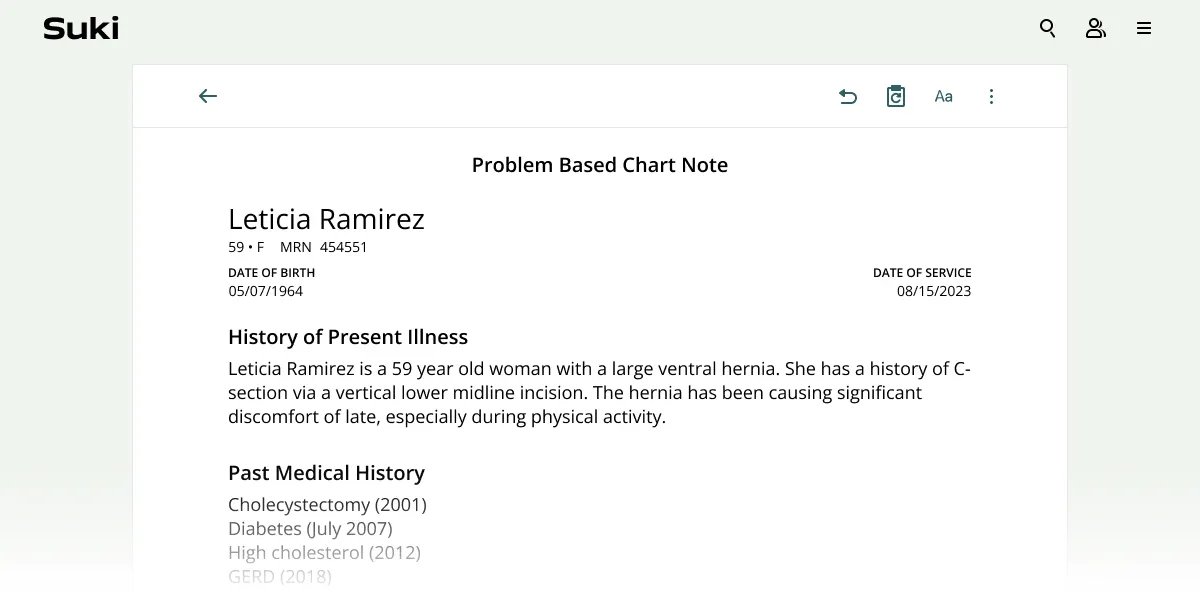
Clinical documentation is a critical part of patient care, and accessing patient data is necessary to achieve this goal. Suki can securely access patient data stored in the most common EHR systems, including Athena, Epic, Cerner and Elation, but it’s also possible to use Suki without an EHR integration.

Suki’s backend includes a dedicated integration layer that manages the flow of data between different EHRs and Suki. This is essential because doctors often face the challenge of navigating various EHRs, each with its own unique quirks and requirements. With Suki, doctors have a uniform interface with a simplified note. Suki manages the dataflow with the EHR to make it easier for doctors to access and update patient data.
Problem 3: Commands and assistance
Context switching can be a disruptive experience that impedes productivity and focus. This is especially important in patient care, where the stakes are high. When a doctor is interacting with a patient, they need to be fully focused on the patient’s needs and concerns, taking in symptoms, family history, and other environmental factors. After that, the doctor has a wide range of tasks to perform, such as reviewing previous reports, noting symptoms and problems, listing areas of investigation in order of priority, and performing differential diagnoses.
In addition, the doctor may need to order medications, tests, schedule follow-ups, and consult with other specialists. Each of these activities requires a high degree of care and attention, and mistakes can have potentially life-threatening consequences. As such, it is crucial that technological solutions minimize the need for context switching and allow doctors to stay focused on their patients as much as possible. To ensure an efficient and immersive experience for doctors, Suki focuses on two key technical requirements.
- Provide an interface for doctors to issue certain requests that they would typically get through context switches, thereby avoiding any loss of focus
- Make the experience immersive with seamless switches between medical dictation and commands so that the doctor’s focus is not lost
To manage context switches effectively, Suki’s voice agent listens concurrently for both dictation and commands when a doctor is in a section of a note. By analyzing the user’s focus on a section, the agent can determine that the doctor intends to dictate. As a result, the voice agent immediately switches to dictation mode without any explicit intervention from the doctor. This ensures that the dictation process remains seamless and minimizes any disruptions to the doctor’s workflow. When doctors want to retrieve data for a patient (blood pressure, hemoglobin levels, etc.) they can ask Suki using commands.
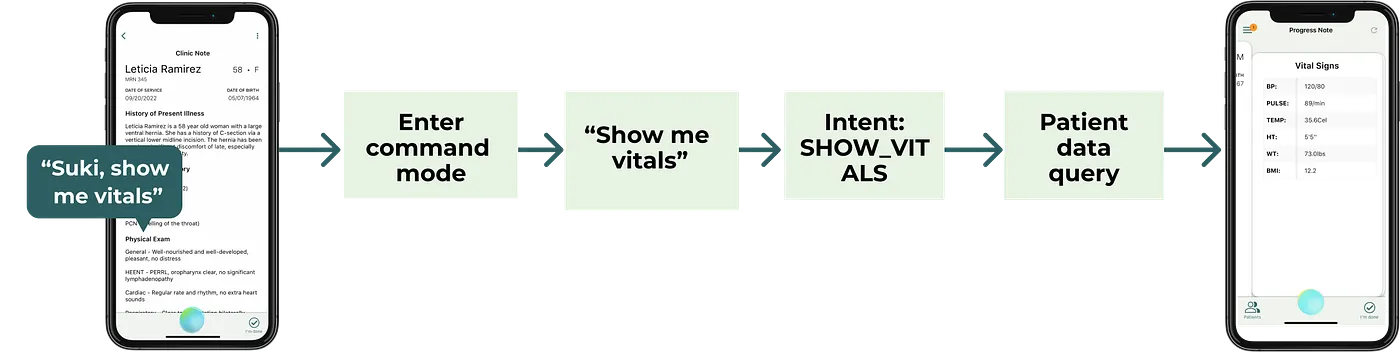
To ensure a smooth dictation experience, commands have to be executed very quickly. To achieve this, the backend relies on in-memory caching of patient data, transcript queues, and shared state. The “syntactic processor” thread listens for dictation and is responsible for handling audio and transcripts when the doctor is actively dictating. The “semantic processor” thread handles commands and transcripts and detects the wake word (“Suki”) to activate.
In the Suki system, the semantic processor is always active and listens for the wake word “Suki”. The syntactic processor, on the other hand, is activated only when the doctor is dictating in a specific section of the note. Due to the nature of audio data being transferred over the network, there are certain elements that are out of Suki’s control, such as packet delivery latency. To address this, a mechanism is needed to measure this latency and account for time differences between when the ASR system detects the audio and when Suki receives the response back from the ASR. Heuristics, which are rules or techniques used to solve problems that are not guaranteed to be optimal, are employed to manage these challenges in real-time.
Problem 4: Ambient
Suki’s ability to carefully listen and process spoken language from doctors prompted users to ask: Can Suki listen to the conversation I am having with my patient and compose a note automatically? A fully automated (or ambient) solution was Suki’s primary aim to begin with. It is the ultimate expression of assistance, and advancements in AI technologies have made it possible today to build ambient capabilities with a high degree of accuracy. An ambient mode poses two unique challenges:
- Semantic equivalency: The note composed ambiently should not violate the intended meaning (diagnosis, description, etc.) of the conversation
- Contextualization: Conversation is just one part of the data. The note should take into account patient details, previous history (if available), and other contextual factors.
Advancements in machine learning, especially in large language models (LLMs), have made it possible to maintain semantic equivalence to a high degree of accuracy. But this alone is not sufficient. Suki assimilates information about patient, previous history, and any other relevant contextual data to create the note and modify the summarization using LLMs.
Additionally, Suki ensures that no PHI data is used for summarization and all user data stays within Suki to ensure privacy and confidentiality. By integrating the voice agent capabilities in ambient mode, Suki provides near-zero intrusion in the clinical documentation experience and creates an ideal assistant for doctors.
Using the right technology
When discussing the Suki backend, it is important to note the technologies that enable its performance. Suki uses the Google Cloud Platform for its infrastructure, while the Backend voice assistants powering the apps are written in Go and Python. This choice of programming language allows Suki to meet the demanding performance benchmarks required for real-time and highly concurrent transcription systems. Additionally, Suki’s EHR services are also using Go, as it excels at data transformation and processing, as well as database interactions.
While these technology choices have proven successful for Suki’s current scale, the company continues to evaluate and evolve its stack as more organizations adopt Suki. Suki’s machine learning and AI team plays a vital role in the core business of intelligent intent detection from ASR text, as well as mapping out slots or parameters within an intent. A detailed description of this system’s architecture is worthy of its own blog post in the future.
The Suki Team
At Suki, one of our core values is to always be learning. Building a solution for doctors and reducing the epidemic of clinician burnout takes concerted effort from many teams who are driven by their passion for technology and dedicated to Suki’s mission. The Suki Engineering team is no different. We’re passionate about the fact that the technology that we’re building is not only complex, challenging, and horizon-expanding but also that it positively impacts the lives of doctors and patients.